
Why the Smartest Startups Are Ditching Big AI for Lean Intelligence
Over the past five years, there has been a simple idea that bigger models are better. OpenAI’s GPT-3 proved in 2020 that throwing more parameters at a problem sent performance through the roof, and the entire industry raced to replicate that logic.
Tech giants raced to build powerful foundation models and invested billions in training systems with hundreds of billions or even trillions of parameters. Startups burned through venture capital on API bills, and enterprises wrote seven-figure checks to cloud providers.
That assumption is fading. Startups are facing a different reality. A new generation of Small Language Models (SLMs) is proving that compact, task-specific AI can deliver equal or better results for most real-world business problems at a fraction of the cost.
That’s why many startups are now shifting toward a leaner approach centered on smaller, specialized AI models. For example, replacing GPT-4 API calls with open-source SLMs can cut inference costs by 5–29×. In addition, small models offer deployment advantages. They deliver sub-second latency on commodity hardware (0.05–0.2s per query for a 7B model vs 2–8s for GPT-4) and make interactive agents smoother.
This guide compares small and large AI models to show how startups save 40–90%+ by using small models or specialized hardware.
The Math That Breaks Big AI’s Business Case
Before we begin comparing SLMs vs LLMs, let’s start where it counts the most, i.e., the invoice.
Companies deploying frontier models (GPT-5 and others) at scale now face monthly cloud bills exceeding $50,000–$100,000 for even modest workloads. That’s a budget-breaker for any startup trying to get to profitability.
The alternative? Serving a 7-billion-parameter SLM is 10–30× cheaper than running a 70–175 billion parameter LLM, which helps cut GPU and cloud/energy expenses by up to 75%.
Anthropic’s Claude Haiku 4.5, a smaller, leaner model, processes data at less than $1 per million input tokens, compared with ~$3 per million for its larger sibling, Sonnet. That cost reduction alone can slash AI spending by over 60%, with comparable accuracy on focused tasks and twice the speed.
When you are running thousands of queries a day on a customer support platform or processing tens of thousands of documents monthly, those per-token savings compound into a completely different business model.
Defining Small vs Large AI Models
There isn’t a hard consensus on “small” vs “large” in generative AI discussions, but a useful rule of thumb is parameter count and compute footprint.
Small language models (SLMs) range from tens of millions to a few billion parameters. In contrast, LLMs often have tens to hundreds of billions of parameters. For example, GPT-3’s base model had 175B parameters and required >350 GB of GPU RAM to serve, whereas many SLMs run entirely on a single 8–16 GB GPU. Quanta Magazine notes that “new smaller models all max out around 10 B parameters.”
SLMs are custom-built or fine-tuned for specific tasks, such as summarization, domain Q&A, and data generation. LLMs aim for broad, open-ended capabilities. Hardware requirements also diverge dramatically. For example, a 7B-parameter model (SLM) may need ~14 GB for 16-bit weights and under 5 GB after 4-bit quantization. By contrast, a 70B model demands ~68 GB (16-bit) or ~20 GB (4-bit), far beyond the capabilities of commodity GPUs.
Table 1 illustrates that a few-billion-parameter SLM can run on a single GPU (or even on-device), with inference latency on the order of 0.05–0.2 s, whereas a 100B+ parameter model requires multiple GPUs and induces seconds of latency.
Table 1: Example Model Sizes and Resource Needs. (Parameters vs GPU memory for 16-bit and 4-bit precision, along with latency and use cases
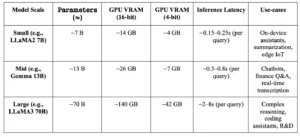
Beyond raw size, big models also entail massive compute requirements. Training the latest frontier models costs on the order of hundreds of millions of dollars (GPT-4: ~$78–$100M, Gemini Ultra: ~$191M), and even inference is costly (~0.36 cents to $0.03 in marginal compute per ChatGPT query, up to $0.10–$0.50 for reasoning models).
What “Small” Actually Means in 2026
SLMs are defined as language models with parameter counts ranging from under 1 billion to around 12–14 billion. They are not dumbed-down versions of large models but are intentionally focused and capable due to better training techniques.
The current SLM landscape is rich:
- Microsoft’s Phi-4 (14B parameters) outperforms models two to five times its size on structured problem-solving benchmarks and runs comfortably on 16GB of hardware.
- Google’s Gemma 2 delivers strong benchmark performance on MMLU, HellaSwag, and other tests and integrates with standard development ecosystems.
- Meta’s Llama 3.2 is available in 1B and 3B variants for edge deployment on mobile and embedded devices.
- Mistral 7B, originally released in 2023, still powers production applications, from mobile apps to local IDE copilots, because it solved the efficiency problem in a way that later, heavier models haven’t replicated.
In 2026, Phi-3, Gemma 2, Mistral 7B, and similar models deliver 80–90% of GPT-4’s quality on focused tasks at a fraction of the cost. For many business tasks, that remaining 10–20% gap doesn’t matter. So, “small” models in this article are those that trade off parameter count (memory, compute, and latency) to gain efficiency on specific tasks.
Why Small Models Can Match Large Ones
The secret behind modern SLMs is smarter optimization. Advances in model compression and efficient architectures, along with external knowledge retrieval, allow compact models to deliver performance once thought possible only with massive AI systems.
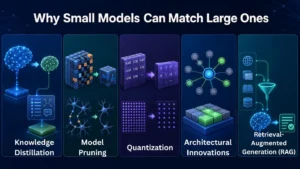
Knowledge Distillation (Teacher–Student Training)
Knowledge distillation trains a smaller “student” model to replicate a larger “teacher” model. The student goes beyond learning final answers. It can also learn the teacher’s reasoning patterns and explanations.
Google researchers demonstrated that a 770M-parameter T5 model enhanced with chain-of-thought distillation outperformed the few-shot-prompted 540B PaLM model, despite being smaller. Similarly, Microsoft’s Orca project used GPT-4-generated reasoning traces to help a 13B model approach GPT-4-level capabilities.
Model Pruning
Pruning removes redundant weights and neurons that contribute little to model performance. Modern pruning techniques produce more efficient models that require less memory and compute while maintaining strong performance.
Quantization (Reduced Precision)
Quantization reduces the precision used to store model weights, such as converting 16-bit values to 8-bit or 4-bit formats. This results in lower memory usage and faster inference with minimal impact on accuracy.
For example, a 70B-parameter model that requires roughly 68 GB in FP16 can shrink to about 20 GB when quantized to 4-bit precision, making deployment far more practical.
Architectural Innovations
New architectures are coming specifically for efficiency. Mixture-of-Experts (MoE) models activate only a portion of their parameters for each task to reduce computation and retain high capability.
For example, a 70B MoE model may use only about 7B active parameters per token. Google’s Gemma-3n uses similar selective activation techniques to enable greater capabilities with much lower memory requirements.
Retrieval-Augmented Generation (RAG)
RAG allows AI systems to retrieve information from external sources in real time. This enables smaller models to access current and domain-specific information without expensive retraining. It also helps reduce hallucinations and expands a model’s effective knowledge base because responses are grounded in retrieved documents.
The Principle No One Says Out Loud
The uncomfortable truth hidden in every bloated AI bill is that most business tasks are narrow, repetitive, and well-defined. For example, they may involve classifying this customer ticket, extracting these product attributes, scoring this sales call, or summarizing this document in this format.
A model that can write poetry, debug code, analyze legal contracts, explain quantum mechanics, and argue about philosophy is spectacular technology. But you don’t need spectacular technology to route a support ticket. You need accurate, inexpensive technology that works fast.
This is the core logic of the SLM movement. When the task is clear, a fine-tuned small model wins on every metric that matters in production, including cost, latency, task-specific accuracy, and privacy.
A case analysis of 287 real-world deployments found the pattern to be remarkably consistent. Fine-tuned small models outperformed general-purpose large models on well-defined, domain-specific tasks and reduced costs by 75%.
A fine-tuned 350M parameter model beat ChatGPT by three times on structured tool calling. Similarly, a fine-tuned 3.8B model outperformed GPT-4o on a specific enterprise classification task.
General reasoning and open-ended creativity still belong to the big models. The massive volume of repetitive enterprise work does not.
Cost and ROI Analysis
The strongest argument for small language models is their economics. SLMs deliver similar business outcomes for many startups while reducing AI spending.
Lower Infrastructure and Compute Costs
Training frontier models can cost tens or even hundreds of millions of dollars, while inference costs continue long after deployment. As AI usage scales, API fees and cloud GPU expenses can become a major operating cost.
Open-source SLMs offer a more efficient alternative. Multiple studies show that smaller models can reduce AI costs by 40–90% while maintaining competitive performance across many business tasks. For example, running a local 7B model costs ~$0.00004-$0.0001 per query (electricity and hardware depreciation) versus $0.025–$0.15 for GPT-4o/GPT-5.5 API usage, representing a 250-1,500x cost reduction for identical workloads.
A practical example comes from Forethought, which reduced inference costs by 66–80% after moving to smaller, fine-tuned models deployed on AWS infrastructure.
Faster Development and Lower Maintenance Costs
Smaller models are also cheaper and faster to fine-tune. Training a 7B model may cost only thousands of dollars, whereas working with much larger models can easily cost six figures.
The benefits extend beyond cost. Arcee AI reduced training time for its 7B legal AI models from 17 hours to 1.6 hours, cutting training costs by nearly 98%.
ROI Gets Serious with Small Models
- Customer Support (90% cost reduction, 3× faster responses): A major e-commerce platform replaced GPT-3.5 API calls with a fine-tuned Mistral 7B for tier-1 support. The result was 90% lower costs, response times three times faster, and equal or better accuracy. Complex queries still escalated to larger models.
- Experian (35% email automation, 8% NPS lift): Experian fine-tuned an Llama 8B model for contact center email responses. Fine-tuning time dropped by 91% (from 86 hours to 8 hours), and 35% of customer emails are now fully automated. Customer satisfaction also rose by 8% in NPS scores.
- CBR (30× faster, 9.4% more accurate than frontier LLMs): Case-Based Research fine-tuned a Llama 3 8B Instruct model on a 150,000-row dataset. It achieved 90% accuracy on its hardest research cases and sustained 0.15-second response times under full-scale traffic. It outperformed a leading fourth-generation LLM in both accuracy and speed at a fraction of the cost.
- AI Agent Tooling (accuracy from 40% to 90% for $1,500): One team replaced a $50,000 fine-tuning quote with a $1,500 consumer GPU running QLoRA on Llama 3.1 8B. Tool-call accuracy rose from 40% to 90%.
- Radiology (hallucinations reduced from 8% to 0%): A peer-reviewed study in Nature npj Digital Medicine tested a Llama 3.2 11B model with RAG against cloud models (GPT-4o mini, Gemini 2.0 Flash, Claude 3.5 Haiku) across 100 simulated clinical scenarios. RAG eliminated hallucinations entirely (0% vs. 8% for the base model, p=0.012) while keeping responses 2–3× faster than cloud alternatives.
The pattern is consistent across industries. Startups that prioritize right-sized models and efficient infrastructure achieve double-digit cost reductions while improving deployment speed and operational efficiency.
In 2025, on-premise AI infrastructure accounted for 57.46% of enterprise AI spending. This share was driven by data-residency requirements and compliance frameworks. Sending data to a third-party API is expensive and untenable in regulated industries. A locally run SLM solves both problems.
Deployment Advantages of Small Models
Smartest startups are leaning towards small models for reasons beyond lower operating costs. These models also unlock deployment options that are difficult or impractical with large AI systems.

On-Device and Edge Deployment
Because of their compact size, SLMs can run directly on smartphones, laptops, IoT devices, and edge servers. This allows companies to process data locally and avoid sending it to cloud-hosted AI services.
For example, healthcare startups can run AI applications on-device to ensure that patient data never leaves the user’s hardware. This is an important advantage for privacy and regulatory compliance. Google’s Gemma-3n is designed for efficient edge deployment using memory-saving techniques such as sparse activation.
Privacy and Compliance
Organizations gain greater control over sensitive information when running AI locally or in a private cloud. Industries such as healthcare, finance, legal services, and government can process confidential data without exposing it to third-party AI providers. This reduces compliance complexity and lowers the risk of handling regulated information.
Lower Latency and Better User Experience
Smaller models deliver faster inference times than large foundation models. Large AI systems may take several seconds to generate responses, but optimized 7B models can respond in fractions of a second.
For real-time applications such as customer support chatbots, voice assistants, and AR experiences, this speed improvement directly enhances user satisfaction and engagement.
Simplified Deployment and Scaling
Large models require distributed GPU clusters, but most SLMs can run on a single GPU or even a CPU. This reduces infrastructure complexity and DevOps overhead.
For example, Unitary is the moderation platform that scales to process millions of videos per day by deploying context-aware AI models and automating infrastructure scaling with Amazon EKS and Karpenter, while reducing costs by 50–70%.
Hardware Flexibility
SLMs also give startups greater freedom in hardware selection. Teams can run models on affordable GPUs/CPUs or specialized AI accelerators without relying on expensive high-end infrastructure.
AWS customer Arcee AI demonstrated this flexibility by combining Trainium and Inferentia chips to train and serve models at lower cost. This ability to optimize performance without being locked into costly hardware gives many startups a competitive advantage.
Tools and Ecosystem for Lean AI
The rise of small language models is accelerating due to the rapid maturity of the ecosystem of tools/frameworks and hardware designed for efficient AI deployment.
A few years ago, deploying AI at scale required significant infrastructure expertise and large budgets. Today, a startup can choose an open-source SLM, optimize it with modern tooling, deploy it on affordable hardware, and launch a production-ready AI service in days.
Optimization and Model Compression Tools
Frameworks such as ONNX Runtime, TensorFlow Lite, PyTorch/XLA, and NVIDIA TensorRT simplify the deployment of quantized and low-precision models. Meanwhile, Hugging Face Optimum, GPTQ, AWQ, and SmoothQuant help teams shrink models without significantly sacrificing performance.
Tools like llama.cpp and Ollama have also made it possible to run powerful AI models directly on laptops and CPUs.
Deployment and MLOps Platforms
Modern deployment platforms simplify serving and scaling small models in production. Solutions such as BentoML, OpenLLM, Hugging Face Accelerate, and Google Vertex AI help teams test, optimize, and deploy AI workloads with minimal infrastructure complexity.
Many organizations now incorporate quantization and model optimization directly into their MLOps pipelines to keep production models fast and cost-efficient.
Hardware Designed for Lean AI
Specialized AI hardware further strengthens the SLM ecosystem. AWS Trainium and Inferentia chips, Google TPUs, ARM processors, and smartphone NPUs can run smaller models far more efficiently than traditional GPU-heavy deployments.
At the same time, open-source projects are bringing SLMs to browsers and edge devices, which is expanding where AI can be deployed.
The Hybrid Play: When Big Models Still Win
This isn’t an argument for burning your GPT subscription and going all in on a 3B-parameter model. The smartest deployments use both.
The emerging best practice is a layered architecture. There should be one central frontier LLM complex and open-ended reasoning tasks, such as novel analysis, creative generation, multi-step problem, etc. Alongside that, there should be multiple specialized SLMs handling the high-volume work that comprises 80–90% of actual queries.
Think of this as the workings of a law firm. The senior partner handles the high-stakes case that requires deep expertise and judgment. The associates handle structured research, document review, and client communication. These are high-volume, process-driven tasks where consistency matters more than brilliance. You don’t pay senior-partner rates for document review.
What All This Means for Startups Right Now
Enterprise generative AI spending surged to $37 billion in 2025, a 3.2× increase from the previous year. However, 70–95% of AI pilots fail to reach sustainable production. The graveyard is full of companies that built impressive demos on expensive APIs but couldn’t justify the unit economics at scale.
The startups that are winning are the ones asking a different set of questions from the start. Not “what’s the most powerful model we can use?” but “what is the actual task, what’s the minimum model size that solves it, and what are our unit economics at 100× volume?”
The global SLM market is projected to grow substantially through 2030, and the technical ecosystem supporting it is becoming more accessible. The models are production-ready, and the tooling is mature. Fine-tuned small models are outperforming larger generic APIs on domain-specific tasks while costing 10–100× less to run.
The founders who understand this are building more defensible products because a model fine-tuned on proprietary data is harder to replicate than a thin wrapper around someone else’s API. They have identified which tasks genuinely require frontier capability and replaced the rest with specialized, cost-effective alternatives. Most find that the frontier model is needed for only 10–20% of their total AI workload.
Bottom Line: The Shift Is Already Underway
The open-source AI market grew 21.1% year-over-year in 2026, expanding from $19.05 billion (2025) to $23.08 billion (2026), with projections reaching $50.03 billion by 2030. On top of that, 68% of companies running AI in production have moved to hybrid/open-weight by April 2026.
This is no longer a niche bet. It’s a mainstream architectural choice, and companies that are slow to recognize it are effectively subsidizing their competitors’ margins.
The next phase of AI advantage is beyond who uses the biggest model. It’s about who builds the right model for the right task and runs it at the lowest cost with faster production shipping.
Lean intelligence is the STRATEGY in 2026.

