
Generative AI Demystified: An Introduction to Large Language Models (LLM) Operations
Since ChatGPT’s launch, generative AI has taken the world by storm. It has transformed what machines can do with language. The core of this revolution is large language models (LLMs), which serve as the advanced engines behind the chatbots we use today.
We all know what we can do with these LLMs, but few understand how they function and manage to interpret our queries and respond accurately. Therefore, we have crafted this comprehensive guide to explore the core concepts of these models, particularly their transformer-based architectures.
We have divided this guide into several sub-sections, beginning with an overview and then exploring key concepts such as attention mechanisms, tokenization, training techniques, fine-tuning, and more.
The Breakdown of Generative Pretrained Transformers (GPT)
The term GPT, which has become popular since the launch of ChatGPT, stands for Generative Pretrained Transformer. These are bots that “generate” new text based on patterns learned during training. The term “pretrained” implies that these models first absorb vast amounts of text data and are then fine-tuned for specialized tasks. The “transformer” is where all the magic happens.
The transformer is the core innovation behind large language models. In simpler terms, it is a neural network- a specialized ML model that predicts the next token based on the context provided by previous tokens.
It employs a layered process to predict the next word. It converts input text into high-dimensional numerical representations, which are processed through complex mechanisms such as attention, and then utilizes probability distributions to predict the subsequent text.
For example, when a transformer is asked to generate new content, it first breaks down the initial snippet and then predicts the next portion using a probability distribution. After adding the next portion, it repeats the process, adding content word by word.
In this way, a GPT tool uses pre-trained data and transformers to generate new text, images, and more.
Diving Inside a Transformer
Transformers are highly structured “factories” where input data is passed sequentially through several specialized blocks. The most critical stages happening inside a transformer include:
- Tokenization: Breaking the input text, image, or audio into manageable pieces.
- Embedding: Converting tokens into high-dimensional vectors.
- Attention Blocks: Allowing vectors to “communicate” to capture context. For example, the word “model” in the machine learning model differs from that in the fashion model. Thus, the vectors communicate to capture the appropriate context and update the vector values accordingly.
- Feed-forward (MLP) Blocks: Further refine the vectors by asking diverse questions.
- Repetition: The process repeats between attention and multi-layered perceptron blocks until all the essential meanings of the content are baked into the final vector in the sequence.
- Output Generation: Generating the probability distribution of vocabulary from the last vector and choosing the most relevant following text.
Each stage contributes to the model’s ability to generate coherent, context-aware text. In the following sections, we will explore how each stage operates.
Tokenization: Turn Input to Data Chunks
When a user provides input, the first stage is tokenization. The content (text, image, or audio) is decomposed into tokens. Tokens are often words or parts of words (subwords), designed to accommodate language’s vast vocabulary and subtle nuances.
Consider the sentence, “The republicans won the elections. ” This sentence is broken into tokens, such as “the, ” “republicans, ” “won, ” “the, ” and “elections. ” The tokenizer might also split words into sub-components to better capture linguistic variety and handle out-of-vocabulary words. For example, longer words might be segmented into more common subword units.
Tokenization allows the model to manage the text with fixed-sized chunks and to process every input systematically.
Embedding: Transform Tokens into High-Dimensional Vectors
After tokenization, each token is converted into a vector using an embedding matrix. Each column in this matrix corresponds to a unique token in the vocabulary. For GPT-3, this vocabulary size is approximately 50,257 tokens. The vectors are high-dimensional and capture the semantic properties of words.
Semantic Space and Embedding Geometry
Imagine each vector as a point in a vast, high-dimensional space. Words with similar meanings are mapped to points that lie closer together. For example, the vector for “king” is positioned in proximity to “queen” or “monarch. ” This geometric arrangement allows for fascinating operations, such as computing differences between vectors. Check out the illustration below, which takes the vector for “woman” minus “man” and adds it to “king” to find a vector close to “queen. ”
The role of embeddings extends beyond individual word representations. Initially, each token’s vector represents its inherent meaning. However, as it progresses through the layers of the transformer, it begins to incorporate context. A word like “model” might start with a general meaning, but in the phrase “fashion model” versus “machine learning model”, its embedding shifts to capture the specific context in which it is used.
Importantly, these embedding vectors are not static. They are part of a vast network of finely-tuned parameters adjusted during training. Each element within the embedding matrix is modified iteratively to capture not only the inherent meaning of a word but also its contextual nuances, essentially acting as learnable ‘control knobs’ that help define the semantic space.
As these parameters evolve, they establish a foundation for the subsequent layers. This guarantees that tokens are represented in a manner that optimally supports the model’s overall understanding.
This dynamic adjustment prepares the attention mechanisms, which build upon these finely tuned embeddings to refine further and contextualize the information flowing through the transformer.
Attention Mechanisms: The Heart of the Transformer
After the initial embeddings are created, the vectors are processed through attention blocks. These blocks are pivotal because they allow each token to “talk” to every other token in the sequence. This communication helps resolve ambiguities and refines the semantic representation.
How Attention Works
In an attention block, each token’s vector interacts with every other token’s vector through a calculation known as a dot product. The dot product measures the alignment between two vectors, with positive values indicating strong similarity, zero indicating orthogonality, and negative values signaling dissimilarity.
The attention mechanism calculates a set of weights that indicate the influence one token has on another. For instance, in the sentence “The model understands the text because it is well-trained”, the word “it” gains relevant context by attending to “model” and “well-trained”. The outcome is a refined representation that captures both the semantic content and the contextual relationships between tokens.
Multi-layered Perceptron (Feed-Forward Layers)
Transformers repeatedly apply two primary operations:
- Attention Blocks: As described above, these let tokens share context.
- Multi-Layer Perceptron (Feed-forward) Blocks: In these, every token is processed in parallel through the same operation. Although less intuitive than attention blocks, these layers can be visualized as posing questions about each token and then updating it based on the answers.
This repetitive sequence of attention and feed-forward layers allows the network to capture complex patterns in the data. Ultimately, the vector corresponding to each token is not merely a representation of that word but a rich, context-aware feature summarizing large stretches of the input text.
Unembedding Matrix & Softmax Function: Generating Probabilities
After numerous layers of transformation, the network reaches its final stage. Here, the last vector(s) are used to predict what comes next. The process involves:
- Unembedding: It is a matrix that maps the final embedding back into the vocabulary space. It converts the nuanced internal representation into a list of scores, one for each token in the vocabulary.
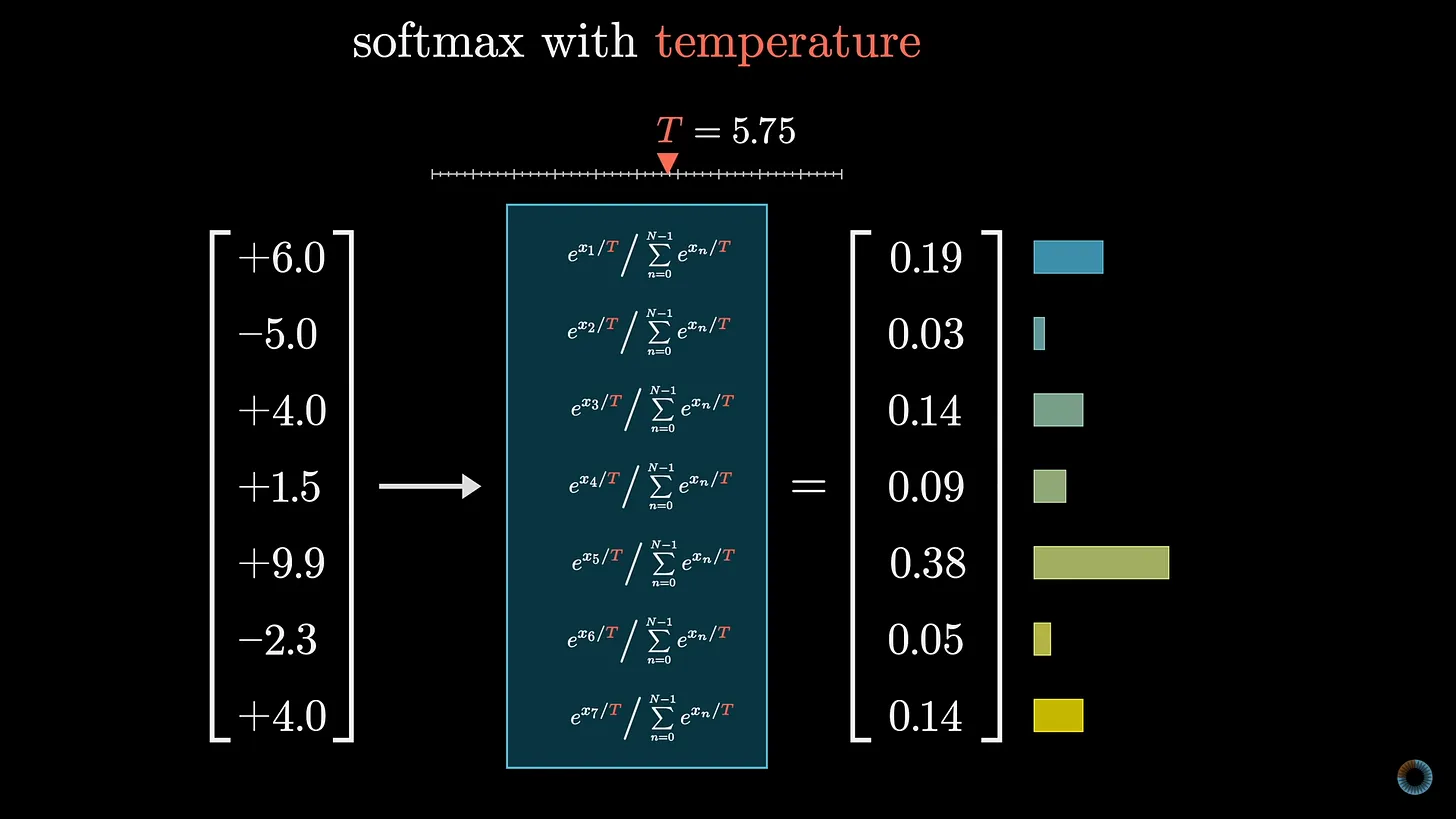
- Softmax Function: This function converts the raw scores (often referred to as logits) into a valid probability distribution. Softmax aims to ensure that each probability lies between 0 and 1 and their total sums are 1; however, it may sometimes deviate from this. The highest probability signifies the most likely next token.
Mathematically, the softmax function operates by exponentiating each input value and dividing by the total sum of these exponentials. This process emphasizes differences; a token with a significantly higher score dominates the probability distribution.
Additionally, introducing a temperature parameter (T) can adjust the output. Higher temperatures yield more uniform distributions, and lower temperatures make the model pick the highest-scoring token more deterministically.
This temperature mechanism is essential for creative applications compared to more deterministic completions. For instance, a moderately high temperature in narrative generation can lead to more original text, while a lower temperature results in predictable completions.
Putting It All Together: Input to Coherent Text
Now that we have covered all the core concepts of how LLM works, let’s quickly summarize how a transformer-based LLM processes text:
- Input Processing: The input text is initially tokenized into manageable pieces. Each token is transformed into a high-dimensional vector using an embedding matrix.
- Attention Flow: The initial vectors pass through layers that enable them to communicate via attention mechanisms, integrating context and refining their representations.
- Feed-forward Refinement: Parallel feed-forward blocks process these vectors, incorporating non-linear transformations to enhance the context-rich representations further.
- Output Projection: The final representations are mapped back into a vocabulary space using the unembedding matrix.
- Probability Distribution: The softmax function converts the raw scores into a probability distribution across the vocabulary, allowing the model to predict the next token.
- Iterative Generation: Adding predicted tokens to the input enables the model to produce long-form text that sustains contextual coherence.
All these steps enable transformers to generate accurate and useful text for the underlying application.
One Architecture, Many Applications: The Flexibility of Transformers
Transformer models provide a rigid structure of layers and operations while maintaining flexibility. The same underlying architecture is applied to a wide variety of tasks:
- Text Generation: Observed in storytelling and chatbots.
- Translation: Converting text from one language to another.
- Image Generation: Models such as DALL-E reinterpret text prompts into visuals using similar underlying principles.
- Speech Processing: Both converting speech to text and vice versa can be accomplished using transformer-based approaches.
This versatility arises from the fact that transformers learn patterns in data. Once the model has mastered the basics of language through tokenization, embeddings, attention, and softmax, it can be adapted to handle various modalities by slightly tweaking or fine-tuning domain-specific data.
The Role of Data and the Training Process
Until now, we have discussed how transformers use vectors, attention flow, probability distribution, and other elements to predict what will happen next. At this point, you may be wondering: What is the purpose of the data and the extensive pre-training process?
The training of transformers involves feeding the model a vast corpus of text data. The model learns by repeatedly predicting the next token in a sequence. For each prediction, the computed probability distribution is compared to the actual following token, and the difference between the prediction and reality is used to adjust the weights through back-propagation.
This repetitive training process enables the network to cultivate a robust internal representation of language. It learns not only the superficial relationships between words but also the context-dependent structures that define human communication. After the training, what began as a random set of weights transforms into a model capable of generating coherent, contextually relevant text.
The Role of Context and Memory
Before we conclude this article, let’s also examine the role of context and memory in LLMs. An intriguing aspect of these models is the concept of context, which refers to the fixed number of tokens the model processes at once. For GPT-3, the context size is 2048 tokens, meaning the model only “sees” that many tokens at a time while making predictions. This limitation explains why early chatbot versions might lose track of a long conversation. Despite this constraint, the model is designed to maximize context extraction and ensure that each vector evolves to represent the token itself and its surroundings in the sequence.
As large language models advance, we now have models that can handle significantly longer context windows and employ specialized memory augmentation mechanisms. These innovations enable models to retain information across longer conversations, preserving coherence and nuance during extended interactions.
Conclusion
The building blocks of generative AI are much more complex than they seem, which has led to the astonishing capabilities seen today. The embedding of words into high-dimensional vector spaces, the precise tuning of parameters, the usage of self-attention to model relationships, and the large-scale training on diverse datasets all contribute to the magic behind these models. We recommend you continue diving deeper into large language models and exploring ways to create more intelligent AI systems.


